
In recent days, We were asked to do an ETL flow using Amazon Web Services. Because we excel in Enterprise Integration we had a particular design in mind to make it happen. The job was pretty simple:
We chose to use different services from Amazon Web Services for this: S3, Simple Workflow (SWF), Simple Queue Service (SQS) and Lambda.
Here a diagram of the solution.
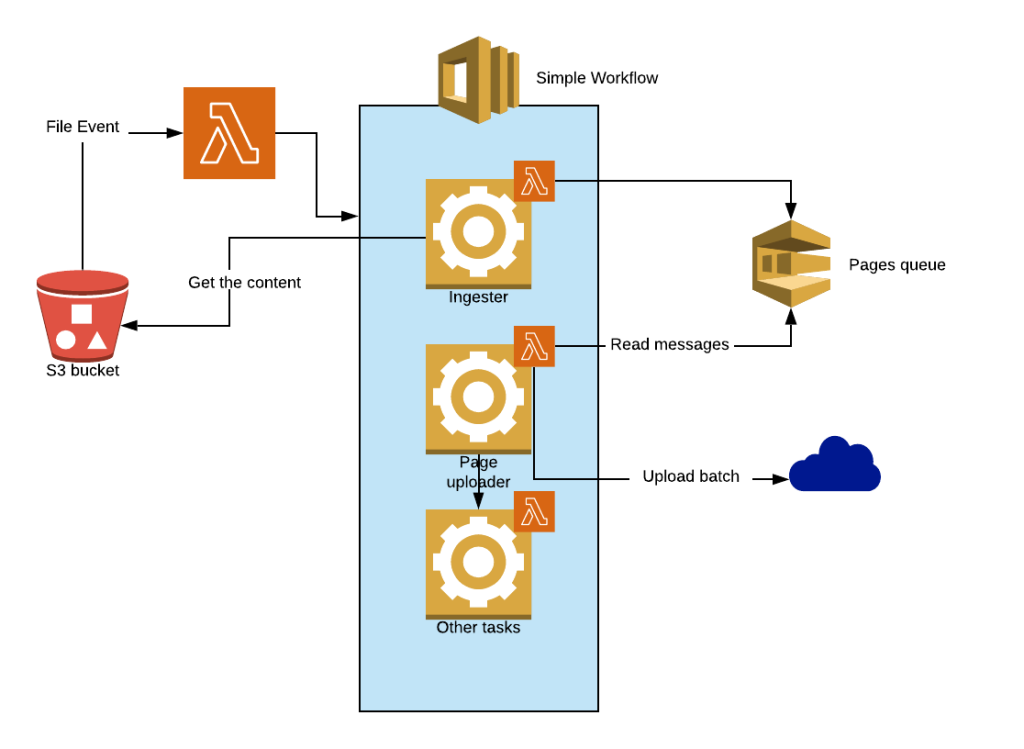
As you can see in the diagram, every task is executed by a Lambda function, so why involve Simple Workflow? The answer is simple: We wanted to create an environment where the sequence of task executions was orchestrated by a single entity, and also be able to share with the different tasks the context of the execution.
If you think of this, we wanted to have something similar to a Flow in a Mule app (MuleSoft Anypoint platform).
It is important to highlight that AWS has some specific limits to execute Lambdas like one Lambda function can only run for a maximum of 5 minutes. Due to these limits, we had to break the tasks into small but cohesive units of work while having a master orchestrator that could run longer than that. Here’s where the shared context comes useful.
While working with SWF and Lambdas, We learned some things that helped us a lot to complete this assignment. Here I’ll show you the situation and solution that worked for me.
One thing you should know about working with SWF is that every output of an activity returns as a Promise to the workflow worker – very similar to a Promise in JavaScript. This Promise returns the output as a serialized object that you need to deserialize if you want to use it as an input for a Lambda function execution directly from the workflow worker. This overhead can be very cumbersome if you use it frequently. In your lambdas you’re supposed to work with objects directly, not serialized forms.
See this sequence diagram to understand it.
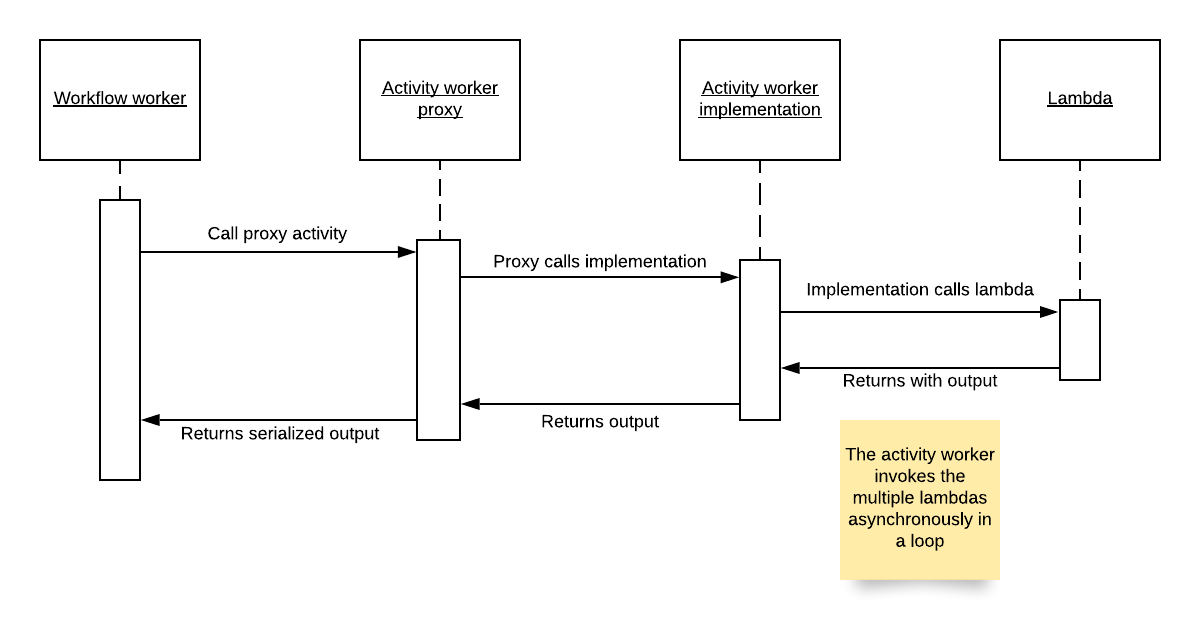
Workflow, activity and lambda sequence diagram.
All in all, we are talking about Enterprise Integration and one of the central pieces is the message. In order to uniformly share information between the workflow and the different Lambdas, it’s better to standardize this practice by using a custom Message object. This Message must contain the workflow context you want to share and the payload. When the Lambda functions are called, they receive this Message object that they use to extract the information required to perform the task fully with no external dependency.
As mentioned before, Lambdas are supposed to run small tasks quickly and independently, therefore they have limits that you should be aware of, such as execution time, memory allocation, ephemeral disk capacity, and the number of threads among others. These are serious constraints when working with big amounts of data and long running processes. In order to overcome these problems, we recommend decomposing the entire file content into small pieces to increase task parallelism and improve performance in a safe manner – actually, this was one of the main reason to use Lambdas since they auto-scale nicely as the parallel processing increases. For this, we divided the file content into packages of records as pages, where each page can contain hundreds or thousands of records. Each page was placed as a message in an SQS queue. The size of the page must consider the limit of 256 KB per message in SQS.
As you see in the diagram above, there’s a poller that is constantly looking for new messages in the SQS queue. This can be a long running process if you expect dozens of thousands of pages. For cases like this, having activities in your flow is very convenient as you can have an activity running for up to one year, this contrasts highly with the 5-minute execution limit of a Lambda function.
Consider the scenario where you have an Activity whose purpose is to read the queue and delegate the upload of the micro-batches to an external system. Commonly, to speed up the execution you make use of threads – note I’m talking about Java but other languages have similar concepts. In this Activity, you may use a loop to create a thread per micro-batch to upload.
Lambda has the limit of 1024 concurrent threads, so if you plan to create a lot of threads to speed up your execution, like uploading micro-batches to the external system mentioned above, first and most importantly, use a thread pool to control the number of threads. We recommend do not create instances of Thread or Runnable, instead, create Java lambda functions for each asynchronous task you want to execute. Make sure you use the AWSLambdaAsyncClientBuilder interface to invoke Lambdas, the ones in AWS, asynchronously.
This approach was particularly successful for a situation where we were not allowed to use an integration platform like Mule. It is also a very nice solution if you just need to integrate AWS services and move lots of data among them.
AWS Simple Workflow and Lambda work pretty well together although they have different goals. Keep in mind that an SWF application needs to be deployed on a machine, like a standalone program, either in your own data center or maybe an EC2 instance, or another IaaS.
This combo will help you to orchestrate and share different contexts, either automated through Activities or manual by using signals, but if what you need is isolated execution and chaining is not relevant to you, then you could use Lambdas only, but the chained execution will no truly isolate them from each other and the starting Lambda may timeout before the Lambdas functions triggered later in the chain finish their execution.
Moreover, every time you work with resources with similar limitations like AWS Lambdas, always bear in mind the restrictions they come with and design your solution based on these constraints, hopefully, in Microflows. Have a read on the Microflows post by Javier Navarro-Machuca, Chief Architect at IO Connect Services.
To increase parallelism we highly recommend using information exchange systems such as queues, transient databases or files. In AWS you can make use of S3, SQS, RDS or DynamoDB (although our preference is SQS for this task)
Stay tuned as we’re a working on a solution that uses Step Functions with Lambdas rather than Simple Workflow for a full Serverless solution integration.



