
This article was originally written by Victor Sosa, Director of Enterprise Integrations. Note: This blog post demonstrates that when fine-tuning a Mule application, the processing of really big volumes of data can be achieved in a matter of minutes. A next blog post, written by Irving Casillas, shows you exactly how to do this but adding resiliency. See Mule Batch - Adding Resiliency to the Manual Pagination Approach.
Bulk processing is one of the most overlooked use cases in enterprise systems, even though they’re very useful when handling big loads of data. In this document, I will showcase different scenarios of bulk upsert to a database using Mule batch components to evaluate some aspects of performance. The objective is to create a best practice of what’s the best configuration of Mule batch components and jobs that process big loads of data for performance purposes. Our goal is to optimize timing executions without compromising computer resources like memory and network connections.
The computer used for this proof has a very commodity configuration as follows:
The software installed is:
The evaluation consists of the processing comma-separated values (.CSV) file which contains 821000+ records and 40 columns for each record. First, we consume the file content, later we transform the data, and then we store them into a database table. The file sizes 741 MB when uncompressed. To ensure that each record has the latest information, the database queries must implement the upsert statement pattern.
Three approaches are shown here:
The first two approaches use the bulk mode of the Insert operation in the Database connector. The third approach uses the Bulk operation in the Database connector.
One important distinction here: The term “upsert execution” is used to refer to the action of inserting a new record but if you find a record with that key then update it with the new values if any. In MySQL this is called “Insert … on duplicate key update” and you can find the documentation here https://dev.mysql.com/doc/refman/5.7/en/insert-on-duplicate.html The term “Insert operation” is used to refer to the Insert configuration element in Mule. You can find documentation here https://docs.mulesoft.com/mule-user-guide/v/3.8/database-connector-reference#insert In other words, we are executing MySQL upsert statements with the Insert operation from the Db component in Mule.
You can find the code in our GitHub repository https://github.com/ioconnectservices/upsertpoc
Some background about the Mule Batch connector. You can configure the block size and the maximum amount of threads of the connect. Moreover, in the Batch Commit component, you can also configure the commit size of the batch. This gives a lot of flexibility in terms of performance and memory tuning.
This flexibility comes with a price: You must calculate the amount of memory the computer will be able to manage for this process only on each block size. This can be easily calculated with the following formula:
Maximum memory = Size of the record * block size * number of maximum threads
For instance, in our test, the size of the record -which is a SQL upsert statement- is 3.1 KB. The settings for the Batch component are 200 records of block size and 25 running threads. This will require a total of 15.13 MB per block size. In this case, this will be executed a minimum of 4105 times approximately (remember the 821000 records?). Also, you must verify that your computer host has enough CPU and memory available for the garbage collection too.
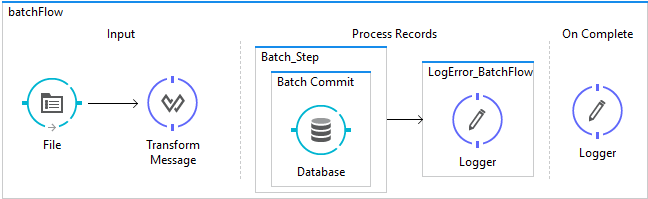
Figure 1. The batch flow.
A simple flow as all the pagination and bulk construction is done by Mule, we just need to worry about the SQL statement and performance.
As explained before, batch jobs are designed to run as fastest as possible by running multiple processes in threads.
The overall idea here is to read the file, then to transform the content into a list and iterate through the list to create a page of records that allows us to construct a series of SQL queries. Later, the queries are sent in bulk fashion to a Database connector with the bulk mode flag enabled.

Figure 2. Custom pagination flow.
This is an approach that was also tested but the results were not as satisfactory as the two above in regards to execution timing but it showed the least memory consumption. The results of the testing are presented next.
The SQL bulk query is constructed manually but the pagination is now handled by the batch job.
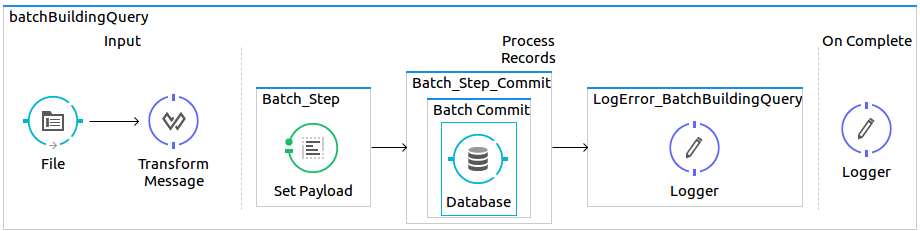
Figure 3. Batch manually building the SQL bulk statement.
Many times, a thoughtful design is more helpful than the out-of-the-box features that any platform may offer. In this scenario, the custom pagination approach is the fastest to upsert the records into the database than the batch approach. However, a couple of things to consider as the outcome of this proof of concept:
As side experiments, I also observed that using the Bulk Execute operation in the Database connector is slower in performance than the Insert operation in bulk mode. Moreover, the parameterized mode allows you to take the data from any source -trusted or untrusted- and still have the queries sanitized.



