
In the previous post Benchmarking Mule Batch Approaches, written by my friend and colleague Victor Sosa, we demonstrated different approaches for processing big files (1-10 GBs) in a batch fashion. The manual pagination strategy proved to be the fastest algorithm, but with one important drawback: it is not resilient. This means that after restarting the server or the application, all the processing progress is lost. Some of the post commenters highlighted that this lack was needed to evaluate this approach against the Mule Batch components equally since the Mule Batch components provide resiliency by default. In this post, I show how to enhance the manual pagination approach by making it resilient. For the testing of this approach I use a Linux virtual machine with the following hardware configuration:
Using the following software:
To process a comma-separated value (.csv) file that contains 821000+ records with 40 columns each, the steps are as follows:
You can find the code in our GitHub repository http://github.com/ioconnectservices/upsertpoc.
We based on the manual pagination approached from the aforementioned article and created a Mule app that processes .cvs files. This time we added a VM connector to decouple the file read and page creation from the bulk page-based database upsert. We configured the VM connector to use a persistent queue so that messages are stored in the hard disk.
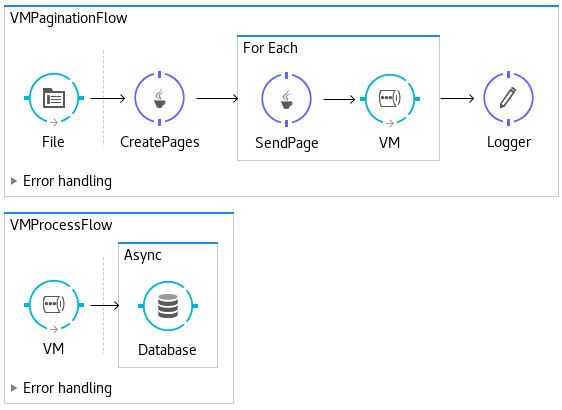
At first, I obtain good results with this approach, but they were 30 seconds slower than the "Custom Pagination" one:
When designing an enterprise system many factors come into the play and we have to make sure it will work even in disastrous events. Adding resiliency to a solution is a must-have in every system. For us, the VM connector brings this resiliency while keeping the execution costs within the desired parameters. Also, you need to know that some performance tuning should be implemented in order to obtain the best results in resiliency without compromising performance.



